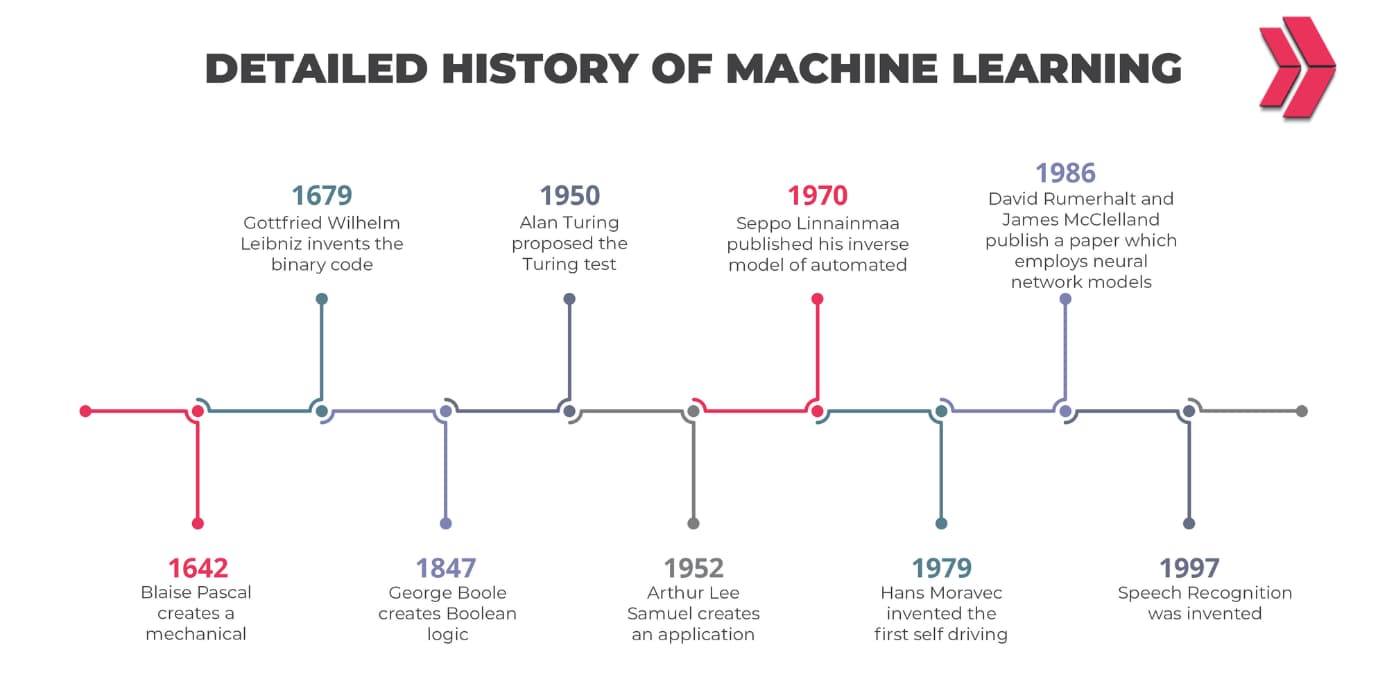
You’ve heard the concepts of deep learning vs machine learning lately but don’t know or understand what they are? So let’s try to learn and understand what these concepts are all together!
After reading this article about deep learning vs. machine learning, I am sure that these concepts will be shaped in your mind much more comfortably. So let’s get started.
What is Machine Learning?
Machine learning is a form of artificial learning that takes place by imitating human learning techniques. For any child to learn to recognize objects/persons, no procedure is explained to that child to introduce the properties of the objects/persons in question and then decide what they are. This child is only shown more than one instance of these objects/persons. Then the human brain automatically starts to identify these features over time (consciously) and learns to recognize objects/ persons. The machine learning model does the same.
In short, machine learning is the science of behaving and learning like humans on computers without directly programming computers by giving human observations to them in the form of information and data. The more different examples the data set contains, the better the machine learning will be; otherwise, the learning will not be good.
For example, a 30-year doctor has made so many diagnoses in his field throughout his professional life that he can quickly diagnose according to the test results. However, a 2-year doctor will not be able to diagnose comfortably because he is just beginning his professional life and perhaps will often need to consult the 30-year doctor.
The data set (experience) on the diseases in the brain of the 30-year doctor is so large that the brain can easily diagnose with a much higher accuracy rate based on past experiences, and it can easily understand which values in test results for diagnosis are important and which are not. But, since the data set (experience) of the 2-year doctor is small, it is natural that the accuracy rate of the disease diagnoses makes it much lower.
Supervised and Unsupervised Learning
Since Supervised and Unsupervised Learning will always appear in machine learning vs deep learning applications, let’s try to understand briefly what they are.
Machine learning algorithms fall into two groups: supervised learning and unsupervised learning. The difference is very simple but essential.
Supervised Learning
Supervised learning problems can be grouped into regression (output = numeric) and classification (output = object) problems depending on the output. It is a type in which a model is trained on a labeled data set. That is, it has both input and output parameters.
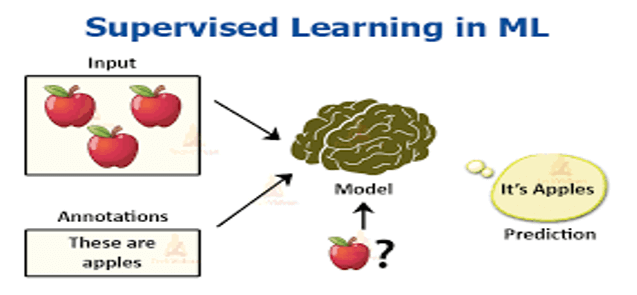
When training an Artificial Intelligence in supervised learning, we tell it expects output by giving it an input. If the output produced by Artificial Intelligence and the output we give are different, it will re-make its calculations. This process is done repeatedly with the data set until the error rate of Artificial Intelligence is minimized.
An example of supervised learning is cancer detection. It learns to predict cancer using historical data. This training data includes inputs (values in cancer tests) and outputs (cancer or not cancer).
Some of the essential supervised learning algorithms are:
- K-Nearest Neighbors
- Naive Bayes
- Linear Regression
- Logistic Regression
- Support Vector Machines (SVM)
- Decision Trees – Random Forests
- Neural Networks (some Neural networks architectures can be unsupervised)
Unsupervised Learning
Unsupervised learning problems can be grouped as clustering and association problems. Unlike supervised learning in unsupervised learning, education data are unlabeled. The system tries to learn without any instructors. It is a type of Machine Learning that transforms raw data into organized / meaningful data.
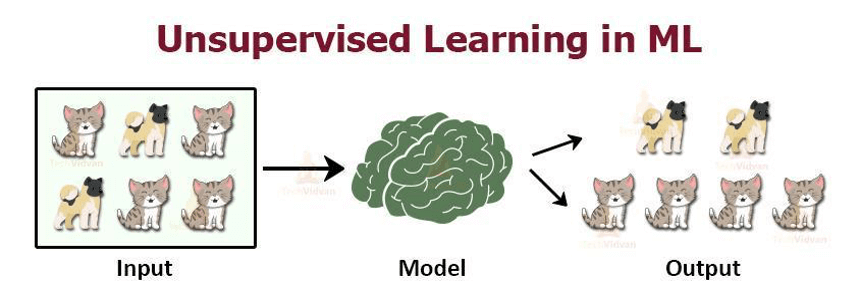
The computer is trained with completely unlabeled data. It is mostly used in descriptive modeling and pattern detection. It is a learning format that we only have the input data but no corresponding output variables.
The purpose of unsupervised learning is to model the structure or distribution that underlies the data we do not have information about. These are called unsupervised learning because there are no correct outputs and no instructors in supervised learning. These algorithms are usually helpful if we don’t know what to look for in the data.
The model learns through observation and finds the structures in the data. When we give a data set to the model, it determines the patterns and relationships between variables by creating clusters. What it can’t do is add labels to the cluster. It can’t call them cats or dogs but will distinguish all cats from dogs.
The Quality Of The Data Set
The success of a machine learning algorithm is directly proportional to the quality of the data set as well as the selected algorithm. When we say quality, we mean the accuracy and completeness of the information in the data set. If the data given as input to the algorithm defines the output wholly and correctly, it will be a high-quality data set.
What is Deep Learning?
Deep learning is a subfield of Machine learning. We mentioned above that the inspiration for machine learning is the human brain, which is the best machine to learn and solve problems. The human brain uses neuronal networks when calculating. Complex connected neuronal networks form the basis for all decisions made based on the various information gathered. The Artificial Neural Network technique is precisely that.
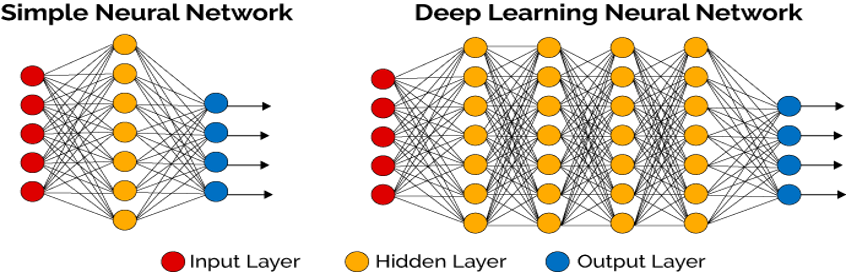
Deep learning uses 3 different layers (input layer, hidden layer (s), output layer) that make up artificial neural networks. Each of these layers is made up of neurons. We will touch on the working logic of these layers below. However, training neural networks for deep learning requires huge computing power and massive amounts of labeled data.
Artificial Neural Network
Let’s take a look at the deep learning working logic for the supervised learning method. Suppose we have a data set with price information according to car specifications (Brand, Model, Year of manufacture, Km, Horsepower). We want to make a car price estimation using this data set.
For estimating car prices, primarily the car specifications are given to the input layer. Since each car brand, car model, year of manufacture, Km, and Hp is a neuron, there are 5 neurons in the input layer. The input layer is responsible for sending these neurons (input data) to the first hidden layer.
In the hidden layer, various calculations are made with activation functions on the input data. The hidden layer(s) sends the values it finds resulting from these calculations to the output layer to make predictions. If the forecast is wrong in the output layer, the incoming values are sent back to the hidden layer to be calculated again. This cycle (called back-propagation) is repeated until it is realized with the smallest error.
The accuracy of the calculations performed in the hidden layer is directly proportional to the number of hidden layers and neurons that make up these layers. For this reason, this is one of the most important issues in deep learning.
What Are The Factors In Price Prediction For Deep Learning?
In the calculations made in the hidden layer, it is tried to determine how much the input data coming from the input layer affects the price estimation we will get from the output layer. A weight coefficient is assigned to each neuron according to its effect on the price estimation. This weighting coefficient is constantly updated until it reaches the most accurate estimate.
Hp has the largest weight coefficient in our example. So, it will have the biggest impact on the price prediction.
Training the Artificial Neural Network (ANN)
For the car price prediction, historical data of car prices are required. Therefore, we need a huge car price list due to many brand and model combinations.
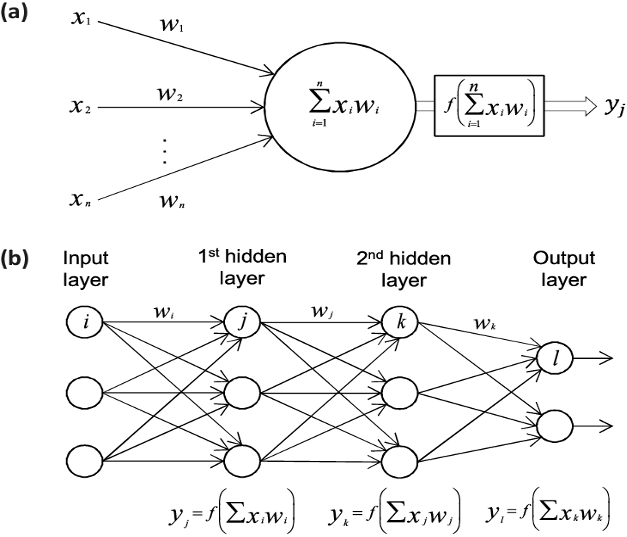
To train Artificial Neural Network (ANN), we need to give the inputs (car brand, car model, year of manufacture, Km and Hp) to ANN, and compare the outputs (estimated prices) we will get from ANN with the real prices in our dataset.
The function that calculates how estimated prices differ from actual prices is called the Cost (loss) Function. We want to do this during the training to reduce the value of the cost function to 0 (zero) as much as possible. In this way, we will be able to make the closest estimates to the real price.
How Can We Reduce The Cost (Loss) Function?
We can change the weights randomly until the cost function gets the closest value to zero, but this is not applicable as the training of the Artificial Neural Network requires huge computing power. Instead, we will use the Gradient Descent optimization algorithm, which does this automatically.
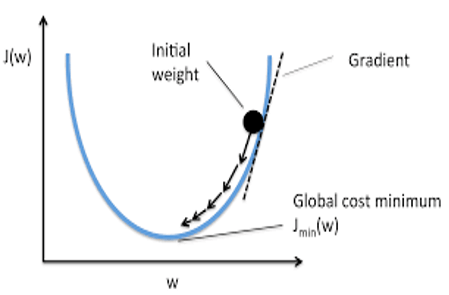
Gradient Descent works by changing the weights bit by bit throughout the backpropagation cycle. It determines the direction of the minimum point by calculating the derivative of the cost function in a certain set of weights. During training, the updated weight is referred to as the learning rate (step size).
When to Use Machine Learning vs Deep Learning?
The major advantage of deep learning is discovering hidden patterns in data and/or deeply understanding the complex relationships between variables and solving these complex problems. Deep learning algorithms detect and learn hidden patterns in the data by themselves and can create very efficient rules using these patterns.
For complex tasks that require dealing with a lot of unstructured data, such as natural language processing, speech recognition, or image classification, deep learning is always at the forefront. However, classical machine learning may be better suited for more straightforward tasks that require simpler feature engineering and do not require the processing of unstructured data.
Clarusway’s Machine Learning Course provides in-depth training in this fascinating field. Clarusway IT Bootcamp provides you with intense and realistic knowledge of using the system in real international situations using real world datasets. Through Machine Learning training, you will use performance metrics to evaluate and update machine learning models in a production environment.
Last Updated on February 14, 2024